Research
Representation learning in reinforcement learning
Stochastic nonlinear control, even with known dynamics and rewards, remains a difficult problem with limited efficient algorithms. While deep reinforcement learning (RL) has advanced the field, these methods often lack rigorous theoretical guarantees and require complex tuning. In this line of work, we take a representation-based viewpoint to reinforcement learning, by using finite-dimensional spectral features for representing value functions via computing spectral decompositions of the transition operator. This approach, based on recent work in linear MDPs, enables more efficient single-agent RL algorithms with strong theoretical guarantees. Beyond the single-agent setting, our approach also scales to continuous state-action network multiagent control, demonstrating success in applications such as Kuramoto frequency synchronization and building heating control.
Selected work:
Stochastic nonlinear nontrol via finite-dimensional spectral dynamic embedding
Zhaolin Ren*, Tongzheng Ren*, Haitong Ma, Na Li, Dai Bo
Transactions on Automatic Control, 2025.
Scalable spectral representations for multi-agent reinforcement learning in network MDPs
Zhaolin Ren*, Runyu Zhang*, Dai Bo, Na Li
AISTATS 2025.
Theory and practice of model-free optimization
In many real-life problems, we may only be able to learn about a system through limited interactive feedback, with no knowledge of the exact form of the underlying dynamics. In optimization and control problems involving such systems, we do not have direct access to the gradients underpinning these problems, making it difficult for us to apply plug-and-play gradient-descent/ascent type methods which are the workhorse of modern machine learning. Instead, to optimize and control these systems, we need to leverage gradient-free optimization techniques, such as zeroth-order optimization and Bayesian optimization. For zeroth-order optimization, I have worked on theoretical guarantees for the ability of two-point zeroth-order algorithms to escape saddle points. This work was inspired by my interest in better understanding the convergence properties of two-point zeroth order gradient estimation, which is an important method often used in practice. For Bayesian optimization (BO), sample efficiency is often paramount as data collection can be expensive both in terms of time and cost. Can we leverage parallel/batch learning techniques to enable more efficient learning? In contrast to standard BO, batch BO presents both advantages (sampling more points per round) and questions (how to intelligently choose the points to sample every round whilst avoiding redundancy?). However, there is a dearth of efficient yet provable batch Bayesian optimization algorithms. To overcome this, I designed a novel batch BO algorithm, called TS-RSR, which samples a batch at each round by minimizing a term which refer to as TS-RSR (Thompson Sampling - Regret to Sigma Ratio). It avoids several of the practical problems faced by existing theoretical-backed algorithms such as Batch Upper-Confidence Bound (BUCB) and Thompson Sampling (TS), such as sensitivity to hyperparameter tuning and lack of redundancy avoidance, but also satisfies a rigorous convergence bound. In practice, we found that our algorithm achieves state-of-the-art performance on a range of synthetic and realistic test functions.
Selected work:
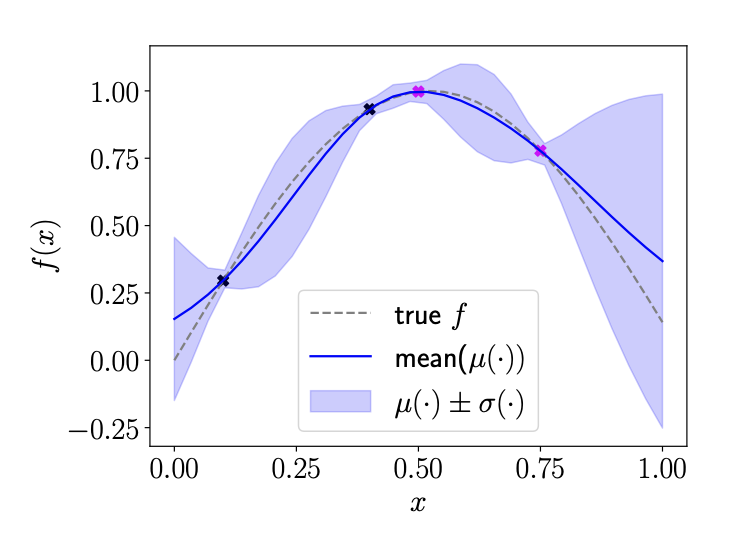
TS-RSR: A provably efficient approach for batch bayesian optimization
Zhaolin Ren, Na Li
SIAM Journal for Optimization, 2025.
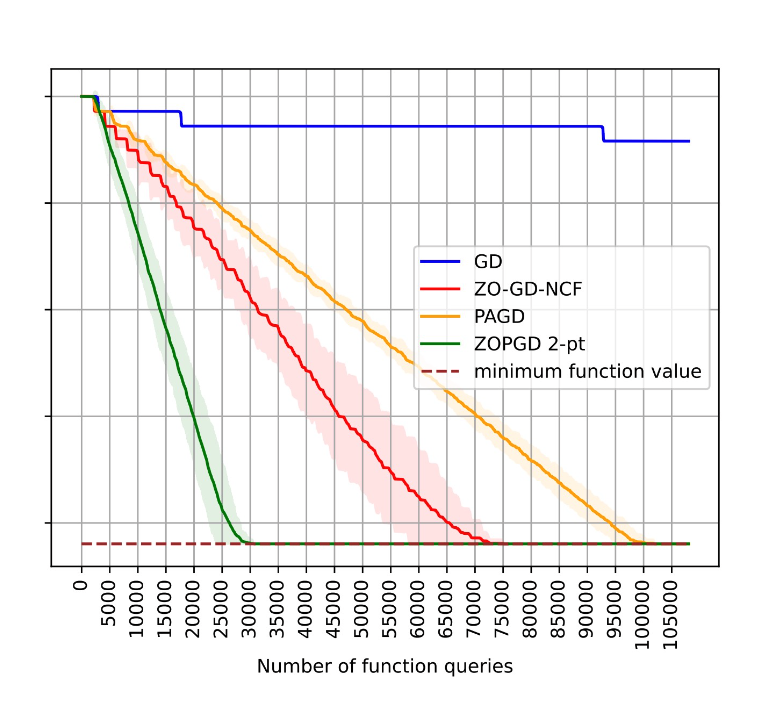
Escaping saddle points in zeroth-order optimization: the power of two-point estimators
Zhaolin Ren, Yujie Tang, Na Li
International Conference on Machine Learning 2023.